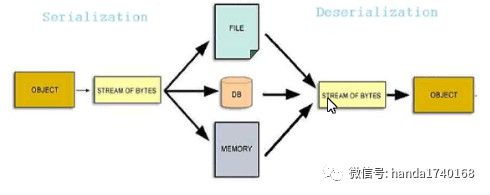
对象序列化
现代编程技术中,面向对象是一个最常见的思想。因此不管是C++Java C#,还是Python JS,都有对象的概念。虽然说面向对象并不是软件开发的“银弹”,但也不失为一种解决复杂逻辑的优秀工具。回到游戏服务器端程序来说,自然我会希望能有一定面向对象方面的支持。所以,从游戏服务器端的整个处理过程来看,我认为,有以下几个地方,是可以用对象来抽象业务数据的:
- 数据传输:我们可以把通过网络传输的数据,看成是一个对象。这样我们可以简单的构造一个对象,然后直接通过网络收、发它。
- 数据缓存:一批在内存中的,可以用对象进行“抽象”。而key-value的模型也是最常见的数据容器,因此我们可以起码把key-value中的value作为对象处理。
- 数据持久化:长久以来,我们使用SQL的二维表结构来持久化数据。但是ORM(对象关系映射)的库一直非常流行,就是想在二维表和对象之间搭起桥梁。现在NoSQL的使用越来越常见,其实也是一种key-value模型。所以也是可以视为一个存放“对象”的工具。
对象序列化的标准模式也很常见,因此我定义成:
- class Serializable {
- public:
- /**
- * 序列化到一个数组中
- * @param buffer 目地缓冲区数组
- * @param buffer_length 缓冲区长度
- * @return 返回写入了 buffer 的数据长度。如果返回 -1 表示出错,比如 buffer_length 不够。
- */
- virtual
- ssize_t
- SerializeTo
- (
- char
- *
- buffer
- ,
- int
- buffer_length
- )
- const
- =
- 0
- ;
- /**
- * @brief 从一个 buffer 中读取 length 个字节,反序列化到本对象。
- *@return 返回 0 表示成功,其他值表示出错。
- */
- virtual
- int
- SerializeFrom
- (
- const
- char
- *
- buffer
- ,
- int
- length
- )
- =
- 0
- ;
- virtual
- ~
- Serializable
- (){}
- };
复制代码
网络传输
有了对象序列化的定义,就可以从网络传输处使用了。因此专门在 Processor 层设计一个收发对象的处理器 ObjectProcessor,它可以接纳一种 ObjectHandler 的对象注册。这个对象根据注册的 Service 名字,负责把收发的接口从 Request, Response 里面的字节数组转换成对象,然后处理。
- // ObjectProcessor 定义
- class
- ObjectProcessor
- :
- public
- ProcessorHelper
- {
- public
- :
- ObjectProcessor
- ();
- virtual
- ~
- ObjectProcessor
- ();
- // 继承自 Processor 处理器函数
- virtual
- int
- Init
- (
- Server
- *
- server
- ,
- Config
- *
- config
- =
- NULL
- );
- // 继承自 Processor 的处理函数
- virtual
- int
- Process
- (
- const
- Request
- &
- request
- ,
- const
- Peer
- &
- peer
- );
- virtual
- int
- Process
- (
- const
- Request
- &
- request
- ,
- const
- Peer
- &
- peer
- ,
- Server
- *
- server
- );
- ///@brief 设置默认处理器,所有没有注册具体服务名字的消息都会用这个消息处理
- inline
- void
- set_default_handler
- (
- ObjectHandler
- *
- default_handler
- )
- {
- default_handler_
- =
- default_handler
- ;
- }
- /**
- * @brief 针对 service_name,注册对应处理的 handler ,注意 handler 本身是带对象类型信息的。
- * @param service_name 服务名字,通过 Request.service 传输
- * @param handler 请求的处理对象
- */
- void
- Register
- (
- const
- std
- ::
- string
- &
- service_name
- ,
- ObjectHandler
- *
- handler
- );
- /**
- * @brief 使用 handler 自己的 GetName() 返回值,注册服务。
- * 如果 handler->GetName() 返回 “” 字符串,则会替换默认处理器对象
- * @param handler 服务处理对象。
- */
- void
- Register
- (
- ObjectHandler
- *
- handler
- );
- ///@brief 关闭此服务
- virtual
- int
- Close
- ();
- private
- :
- std
- ::
- map
- <
- std
- ::
- string
- ,
- ObjectHandler
- *>
- handler_table_
- ;
- Config
- *
- config_
- ;
- ObjectHandler
- *
- default_handler_
- ;
- int
- ProcessBy
- (
- const
- Request
- &
- request
- ,
- const
- Peer
- &
- peer
- ,
- ObjectHandler
- *
- handler
- ,
- Server
- *
- server
- =
- NULL
- );
- int
- DefaultProcess
- (
- const
- Request
- &
- request
- ,
- const
- Peer
- &
- peer
- ,
- Server
- *
- server
- =
- NULL
- );
- bool
- InitHandler
- (
- ObjectHandler
- *
- handler
- );
- };
- // ObjectHandler 定义
- class
- ObjectHandler
- :
- public
- Serializable
- ,
- public
- Updateable
- {
- public
- :
- ObjectHandler
- ();
- virtual
- ~
- ObjectHandler
- ()
- ;
- virtual
- void
- ProcessRequest
- (
- const
- Peer
- &
- peer
- );
- virtual
- void
- ProcessRequest
- (
- const
- Peer
- &
- peer
- ,
- Server
- *
- server
- );
- /**
- * DenOS 用此方法确定进行服务注册,你应该覆盖此方法。
- * 默认名字为空,会注册为“默认服务”,就是所有找不到对应名字服务的请求,都会转发给此对象处理。
- * @return 注册此服务的名字。在 Request.service 字段中传输。
- */
- virtual
- std
- ::
- string
- GetName
- ()
- ;
- int
- Reply
- (
- const
- char
- *
- buffer
- ,
- int
- length
- ,
- const
- Peer
- &
- peer
- ,
- const
- std
- ::
- string
- &
- service_name
- =
- “”
- ,
- Server
- *
- server
- =
- NULL
- )
- ;
- int
- Inform
- (
- char
- *
- buffer
- ,
- int
- length
- ,
- const
- std
- ::
- string
- &
- session_id
- ,
- const
- std
- ::
- string
- &
- service_name
- ,
- Server
- *
- server
- =
- NULL
- );
- int
- Inform
- (
- char
- *
- buffer
- ,
- int
- length
- ,
- const
- Peer
- &
- peer
- ,
- const
- std
- ::
- string
- &
- service_name
- =
- “”
- ,
- Server
- *
- server
- =
- NULL
- );
- virtual
- int
- Init
- (
- Server
- *
- server
- ,
- Config
- *
- config
- );
- /**
- * 如果需要在主循环中进行操作,可以实现此方法。
- * 返回值小于 0 的话,此任务会被移除循环
- */
- virtual
- int
- Update
- ()
- {
- return
- 0
- ;
- }
- protected
- :
- Server
- *
- server_
- ;
- std
- ::
- map
- <
- int
- ,
- MessageHeader
- >
- header_map_
- ;
- Response
- response_
- ;
- Notice
- notice_
- ;
- };
复制代码
由于我们对于可序列化的对象,要求一定要实现Serializable这个接口,所以所有需要收发的数据,都要定义一个类来实现这个接口。但是,这种强迫用户一定要实现某个接口的方式,可能会不够友好,因为针对业务逻辑设计的类,加上一个这种接口,会比较繁琐。为了解决这种问题,我利用C++的模板功能,对于那些不想去实现Serializable的类型,使用一个额外的Pack()/Upack()模板方法,来插入具体的序列化和反序列化方法(定义ObjectHandlerCast模板)。这样除了可以减少实现类型的代码,还可以让接受消息处理的接口方法ProcessObject()直接获得对应的类型指针,而不是通过Serializable来强行转换。在这里,其实也有另外一个思路,就是把Serializable设计成一个模板类,也是可以减少强制类型转换。但是我考虑到,序列化和反序列化,以及处理业务对象,都是使用同样一个(或两个,一个输入一个输出)模板类型参数,不如直接统一到一个类型里面好了。
- // ObjectHandlerCast 模板定义
- /**
- * 用户继承这个模板的实例化类型,可以节省关于对象序列化的编写代码。
- * 直接编写开发业务逻辑的函数。
- */
- template
- <
- typename
- REQ
- ,
- typename
- RES
- =
- REQ
- >
- class
- ObjectHandlerCast
- :
- public
- ObjectHandler
- {
- public
- :
- ObjectHandlerCast
- ()
- :
- req_obj_
- (
- NULL
- ),
- res_obj_
- (
- NULL
- ),
- buffer_
- (
- NULL
- )
- {
- buffer_
- =
- new
- char
- [
- Message
- ::
- MAX_MAESSAGE_LENGTH
- ];
- bzero
- (
- buffer_
- ,
- Message
- ::
- MAX_MAESSAGE_LENGTH
- );
- }
- virtual
- ~
- ObjectHandlerCast
- ()
- {
- delete
- []
- buffer_
- ;
- }
- /**
- * 对于不想使用 obj_ 成员来实现 Serializable 接口的,可以实现此接口
- */
- virtual
- int
- Pack
- (
- char
- *
- buffer
- ,
- int
- length
- ,
- const
- RES
- &
- object
- )
- const
- {
- return
- –
- 1
- ;
- }
- virtual
- int
- Unpack
- (
- const
- char
- *
- buffer
- ,
- int
- length
- ,
- REQ
- *
- object
- )
- {
- return
- –
- 1
- ;
- }
- int
- ReplyObject
- (
- const
- RES
- &
- object
- ,
- const
- Peer
- &
- peer
- ,
- const
- std
- ::
- string
- &
- service_name
- =
- “”
- )
- {
- res_obj_
- =
- &
- object
- ;
- int
- len
- =
- SerializeTo
- (
- buffer_
- ,
- Message
- ::
- MAX_MAESSAGE_LENGTH
- );
- if
- (
- len
- <
- 0
- )
- return
- –
- 1
- ;
- return
- Reply
- (
- buffer_
- ,
- len
- ,
- peer
- ,
- service_name
- );
- }
- int
- InformObject
- (
- const
- std
- ::
- string
- &
- session_id
- ,
- const
- RES
- &
- object
- ,
- const
- std
- ::
- string
- &
- service_name
- )
- {
- res_obj_
- =
- &
- object
- ;
- int
- len
- =
- SerializeTo
- (
- buffer_
- ,
- Message
- ::
- MAX_MAESSAGE_LENGTH
- );
- if
- (
- len
- <
- 0
- )
- return
- –
- 1
- ;
- return
- Inform
- (
- buffer_
- ,
- len
- ,
- session_id
- ,
- service_name
- );
- }
- virtual
- void
- ProcessRequest
- (
- const
- Peer
- &
- peer
- ,
- Server
- *
- server
- )
- {
- REQ
- *
- obj
- =
- req_obj_
- ;
- ProcessObject
- (*
- obj
- ,
- peer
- ,
- server
- );
- delete
- obj
- ;
- req_obj_
- =
- NULL
- ;
- }
- virtual
- void
- ProcessObject
- (
- const
- REQ
- &
- object
- ,
- const
- Peer
- &
- peer
- )
- {
- ERROR_LOG
- (
- “This object have no process handler.”
- );
- }
- virtual
- void
- ProcessObject
- (
- const
- REQ
- &
- object
- ,
- const
- Peer
- &
- peer
- ,
- Server
- *
- server
- )
- {
- ProcessObject
- (
- object
- ,
- peer
- );
- }
- protected
- :
- REQ
- *
- req_obj_
- ;
- const
- RES
- *
- res_obj_
- ;
- private
- :
- char
- *
- buffer_
- ;
- virtual
- ssize_t
- SerializeTo
- (
- char
- *
- buffer
- ,
- int
- buffer_length
- )
- const
- {
- ssize_t
- ret
- =
- 0
- ;
- ret
- =
- Pack
- (
- buffer
- ,
- buffer_length
- ,
- *
- res_obj_
- );
- return
- ret
- ;
- }
- virtual
- int
- SerializeFrom
- (
- const
- char
- *
- buffer
- ,
- int
- length
- )
- {
- req_obj_
- =
- new
- REQ
- ();
- // 新建一个对象,为了协程中不被别的协程篡改
- int
- ret
- =
- Unpack
- (
- buffer
- ,
- length
- ,
- req_obj_
- );
- if
- (
- ret
- )
- {
- delete
- req_obj_
- ;
- req_obj_
- =
- NULL
- ;
- }
- return
- ret
- ;
- }
- };
复制代码
任何类型的对象,如果想要在这个框架中以网络收发,只要为他写一个模板,完成Pack()和UnPack()这两个方法,就完成了。看起来确实方便。(如果想节省注册的时候编写其“类名”,还需要完成一个简单的GetName()方法)
当我完成上面的设计,不禁赞叹C++对于模板支持的好处。由于模板可以在编译时绑定,只要是具备“预设”的方法的任何类型,都可以自动生成一个符合既有继承结构的类。这对于框架设计来说,是一个巨大的便利。而且编译时绑定也把可能出现的类型错误,暴露在编译期。————对比那些可以通过反射实现同样功能的技术,其实是更容易修正的问题。
缓冲和持久化
数据传输的对象序列化问题解决后,下来就是缓存和持久化。由于缓存和持久化,我的设计都是基于Map接口的,也就是一种Key-Value的方式,所以就没有设计模板,而是希望用户自己去实现Serializable接口。但是我也实现了最常用的几种可序列化对象的实现代码:
- 固定长度的类型,比如int。序列化其实就是一个memcpy()而已。
- std::string字符串。这个需要使用c_str()变成一个字节数组。
- JSON格式串。使用了某个开源的json解析器。推荐GITHUB上的Tencent/RapidJson。
数据缓冲
数据缓冲这个需求,虽然在互联网领域非常常见,但是游戏的缓冲和其他一些领域的缓冲,实际需求是有非常大的差别。这里的差别主要有:
游戏的缓冲要求延迟极低,而且需要对服务器性能占用极少,因为游戏运行过程中,会有非常非常频繁的缓冲读写操作。举个例子来说,一个“群体伤害”的技能,可能会涉及对几十上百个数据对象的修改。而且这个操作可能会以每秒几百上千次的频率请求服务器。如果我们以传统的memcache方式来建立缓冲,这么高频率的网络IO往往不能满足延迟的要求,而且非常容易导致服务器过载。
游戏的缓冲数据之间的关联性非常强。和一张张互不关联的订单,或者一条条浏览结果不一样。游戏缓冲中往往存放着一个完整的虚拟世界的描述。比如一个地区中有几个房间,每个房间里面有不通的角色,角色身上又有各种状态和道具。而角色会在不同的房间里切换,道具也经常在不同角色身上转移。这种复杂的关系会导致一个游戏操作,带来的是多个数据的同时修改。如果我们把数据分割放在多个不同的进程上,这种关联性的修改可能会让进程间通信发生严重的过载。
游戏的缓冲数据的安全性具有一个明显的特点:更新时间越短,变换频率越大的数据,安全性要求越低。这对于简化数据缓冲安全性涉及,非常具有价值。我们不需要过于追求缓冲的“一致性”和“时效”,对于一些异常情况下的“脏”数据丢失,游戏领域的忍耐程度往往比较高。只要我们能保证最终一致性,甚至丢失一定程度以内的数据,都是可以接受的。这给了我们不挑战CAP定律的情况下,设计分布式缓冲系统的机会。
基本模型
基于上面的分析,我首先希望是建立一个足够简单的缓冲使用模型,那就是Map模型。
- class
- DataMap
- :
- public
- Updateable
- {
- public
- :
- DataMap
- ();
- virtual
- ~
- DataMap
- ();
- /**
- * @brief 对于可能阻塞的异步操作,需要调用这个接口来驱动回调。
- */
- virtual
- int
- Update
- (){
- return
- 0
- ;
- }
- /**
- * @brief 获取 key 对应的数据。
- * @param key 数据的 Key
- * @param value_buf 是输出缓冲区指针
- * @param value_buf_len 是缓冲区最大长度
- * @return 返回 -1 表示找不到这个 key,返回 -2 表示 value_buf_len 太小,不足以读出数据。其他负数表示错误,返回 >= 0 的值表示 value 的长度
- */
- virtual
- int
- Get
- (
- const
- std
- ::
- string
- &
- key
- ,
- char
- *
- value_buf
- ,
- int
- value_buf_len
- )
- =
- 0
- ;
- virtual
- int
- Get
- (
- const
- std
- ::
- string
- &
- key
- ,
- Serializable
- *
- value
- );
- /**
- * @brief 异步 Get 的接口
- * @param key 获取数据的 Key
- * @param callback 获取数据的回调对象,如果 key 不存在, FetchData() 参数 value_buf 会为 NULL
- * @return 返回 0 表示发起查询成功,其他值表示错误。
- */
- virtual
- int
- Get
- (
- const
- std
- ::
- string
- &
- key
- ,
- DataMapCallback
- *
- callback
- )
- =
- 0
- ;
- /**
- * @brief 覆盖、写入key对应的缓冲数据。
- * @return 成功返回0。 返回 -1 表示value数据太大,其他负数表示其他错误
- */
- virtual
- int
- Put
- (
- const
- std
- ::
- string
- &
- key
- ,
- const
- char
- *
- value_buf
- ,
- int
- value_buf_len
- )
- =
- 0
- ;
- virtual
- int
- Put
- (
- const
- std
- ::
- string
- &
- key
- ,
- const
- Serializable
- &
- value
- );
- /**
- * 写入数据的异步接口,使用 callback 来通知写入结果
- * @param key 数据 key
- * @param value 数据 Value
- * @param callback 写入结果会调用此对象的 PutResult() 方法
- * @return 返回 0 表示准备操作成功
- */
- virtual
- int
- Put
- (
- const
- std
- ::
- string
- &
- key
- ,
- const
- Serializable
- &
- value
- ,
- DataMapCallback
- *
- callback
- );
- virtual
- int
- Put
- (
- const
- std
- ::
- string
- &
- key
- ,
- const
- char
- *
- value_buf
- ,
- int
- value_buf_len
- ,
- DataMapCallback
- *
- callback
- );
- /**
- * 删除 key 对应的数据
- * @return 返回 0 表示成功删除,返回 -1 表示这个 key 本身就不存在,其他负数返回值表示其他错误。
- */
- virtual
- int
- Remove
- (
- const
- std
- ::
- string
- &
- key
- )
- =
- 0
- ;
- virtual
- int
- Remove
- (
- const
- std
- ::
- string
- &
- key
- ,
- DataMapCallback
- *
- callback
- );
- /**
- * 是否有 Key 对应的数据
- *@return 返回 key 值表示找到,0 表示找不到
- */
- virtual
- int
- ContainsKey
- (
- const
- std
- ::
- string
- &
- key
- )
- =
- 0
- ;
- /**
- * 异步 ContainsKey 接口,如果 key 不存在, FetchData() 参数 value_buf 会为 NULL。
- * 如果 key 存在,value_buf 则不为NULL,但也不保证指向任何可用数据。可能是目标数值,
- * 也可能内部的某个空缓冲区。如果是在本地的数据,就会是目标数据,如果是远程的数据,
- * 为了减少性能就不会传入具体的 value 数值。
- */
- virtual
- int
- ContainsKey
- (
- const
- std
- ::
- string
- &
- key
- ,
- DataMapCallback
- *
- callback
- )
- =
- 0
- ;
- /**
- * 遍历整个缓存。
- * @param callback 每条记录都会调用 callback 对象的 FetchData() 方法
- * @return 返回 0 表示成功,其他表示错误。
- */
- virtual
- int
- GetAll
- (
- DataMapCallback
- *
- callback
- )
- =
- 0
- ;
- /**
- * 获取整个缓存的数据
- * @param result 结果会放在这个 map 里面,记得每条记录中的 Bytes 的 buffer_ptr 需要 delete[]
- * @return 返回 0 表示成功,其他表示错误
- */
- virtual
- int
- GetAll
- (
- std
- ::
- map
- <
- std
- ::
- string
- ,
- Bytes
- >*
- result
- );
- private
- :
- char
- *
- tmp_buffer_
- ;
- };
复制代码
这个接口其实只是一个std::map的简单模仿,把key固定成string,而把value固定成一个buffer或者是一个可序列化对象。另外为了实现分布式的缓冲,所有的接口都增加了回调接口。
可以用来充当数据缓存的业界方案其实非常多,他们包括:
堆内存,这个是最简单的缓存容器
Redis
Memcached
ZooKeeper这个自带了和进程关联的数据管理
由于我希望这个框架,可以让程序自由的选用不同的缓冲存储“设备”,比如在测试的时候,可以不按照任何其他软件,直接用自己的内存做缓冲,而在运营或者其他情况下,可以使用Redis或其他的设备。所以我们可以编写代码来实现上面的DataMap接口,以实现不同的缓冲存储方案。当然必须要把最简单的,使用堆内存的实现完成:RamMap
分布式设计
如果作为一个仅仅在“本地”服务器使用的缓冲,上面的DataMap已经足够了,但是我希望缓存是可以分布式的。不过,并不是任何的数据,都需要分布式存储,因为这会带来更多延迟和服务器负载。因此我希望设计一个接口,可以在使用时指定是否使用分布式存储,并且指定分布式存储的模式。
根据经验,在游戏领域中,分布式存储一般有以下几种模式:
本地模式如果是分区分服的游戏,数据缓存全部放在一个地方即可。或者我们可以用一个Redis作为缓存存储点,然后多个游戏服务进程共同访问它。总之对于数据全部都缓存在一个地方的,都可以叫做本地模式。这也是最简单的缓冲模式。
按数据类型分布这种模式和“本地模式”的差别,仅仅在于数据内容不同,就放在不同的地方。比如我们可以所有的场景数据放在一个Redis里面,然后把角色数据放在另外一个Redis里面。这种分布节点的选择是固定,仅仅根据数据类型来决定。这是为了减缓某一个缓冲节点的压力而设计。或者你对不同数据有缓冲隔离的需求:比如我不希望对用户的缓冲请求负载,影响对支付服务的缓冲请求负载。
按数据的Key分布这是最复杂也最有价值的一种分布式缓存。因为缓冲模式是按照Key-Vaule的方式来存放的,所以我们可以把不同的Key的数据分布到不同节点上。如果刚好对应的Key数据,是分布在“本地”的,那么我们将获得本地操作的性能!这种缓冲
按复制分布就是多个节点间的数据一摸一样,在修改数据的时候,会广播到所有节点,这种是典型的读多写少性能好的模型。
在游戏开发中,我们往往习惯于把进程,按游戏所需要的数据来分布。比如我们会按照用户ID,把用户的状态数据,分布到不同的机器上,在登录的时候,就按照用户ID去引导客户端,直接连接到对应的服务器进程处。或者我们会把每个战斗副本或者游戏房间,放在不同的服务器上,所有的战斗操作请求,都会转发到对应的存放其副本、房间数据的服务器上。在这种开发中,我们会需要把大量的数据包路由、转发代码耦合到业务代码中。
如果我们按照上面的第3种模型,就可以把按“用户ID”或者“房间ID”分布的事情,交给底层缓冲模块去处理。当然如果仅仅这样做,也许会有大量的跨进程通信,导致性能下降。但是我们还可以增加一个“本地二级缓存”的设计,来提高性能。具体的流程大概为:
取key在本地二级缓存(一般是RamMap)中读写数据。如果没有则从远端读取数据建立缓存,并在远端增加一条“二级缓存记录”。此记录包含了二级所在的服务器地址。
按key计算写入远端数据。根据“二级缓存记录”广播“清理二级缓存”的消息。此广播会忽略掉刚写入远端数据的那个服务节点。(此行为是异步的)
只要不是频繁的在不同的节点上写入同一个Key的记录,那么二级缓存的生存周期会足够长,从而提供足够好的性能。当然这种模式在同时多个写入记录时,有可能出现脏数据丢失或者覆盖,但可以再添加上乐观锁设计来防止。不过对于一般游戏业务,我们在Key的设计上,就应该尽量避免这种情况:如果涉及非常重要的,多个用户都可能修改的数据,应该避免使用“二级缓存”功能的模型3缓存,而是尽量利用服务器间通信,把请求集中转发到数据所在节点,以模式1(本地模式)使用缓冲。
以下为分布式设计的缓冲接口。
- /**
- * 定义几种网络缓冲模型
- */
- enum
- CacheType
- {
- TypeLocal
- ,
- ///< 本地
- TypeName
- ,
- ///< 按 Cache 名字分布
- TypeKey
- ,
- ///< 先按 Cache 名字分布,再按数据的 key 分布
- TypeCopy
- ///< 复制型分布
- };
- /**
- * @brief 定义了分布式缓存对象的基本结构
- */
- class
- Cache
- :
- public
- DataMap
- {
- public
- :
- /**
- * @brief 连接集群。
- * @return 返回是否连接成功。
- */
- static
- bool
- EnsureCluster
- (
- Config
- *
- config
- =
- NULL
- );
- /**
- * 获得一个 Cache 对象。
- * @attention 如果第一次调用此函数时,输入的 type, local_data_map 会成为这个 Cache 的固定属性,以后只要是 name 对的上,都会是同一个 Cache 对象。
- * @param name 为名字
- * @param type 此缓存希望是哪种类型
- * @param local_data_map 为本地存放的数据容器。
- * @return 如果是 NULL 表示已经达到 Cache 数量的上限。
- */
- static
- Cache
- *
- GetCache
- (
- const
- std
- ::
- string
- &
- name
- ,
- CacheType
- type
- ,
- DataMap
- *
- local_data_map
- );
- /**
- * 获得一个 Cache 对象。
- * @param name 为名字
- * @param local_data_map 为本地存放的数据容器。
- * @note 如果第一次调用此函数时,输入的 type, class M 会成为这个 Cache 的固定属性,以后只要是 name 对的上,都会是同一个 Cache 对象。
- * @return 如果是 NULL 表示已经达到 Cache 数量的上限。
- */
- template
- <
- class
- M
- >
- static
- Cache
- *
- GetCache
- (
- const
- std
- ::
- string
- &
- name
- ,
- CacheType
- type
- ,
- int
- *
- data_map_arg1
- =
- NULL
- )
- {
- DataMap
- *
- local_data_map
- =
- NULL
- ;
- std
- ::
- map
- <
- std
- ::
- string
- ,
- DataMap
- *>::
- iterator
- it
- =
- cache_store_
- .
- find
- (
- name
- );
- if
- (
- it
- !=
- cache_store_
- .
- end
- ())
- {
- local_data_map
- =
- it
- ->
- second
- ;
- }
- else
- {
- if
- (
- data_map_arg1
- !=
- NULL
- )
- {
- local_data_map
- =
- new
- M
- (*
- data_map_arg1
- );
- }
- else
- {
- local_data_map
- =
- new
- M
- ();
- }
- cache_store_
- [
- name
- ]
- =
- local_data_map
- ;
- }
- return
- GetCache
- (
- name
- ,
- type
- ,
- local_data_map
- );
- }
- /**
- * 删除掉本进程内存放的 Cache
- */
- static
- void
- RemoveCache
- (
- const
- std
- ::
- string
- &
- name
- );
- explicit
- Cache
- (
- const
- std
- ::
- string
- &
- name
- );
- virtual
- ~
- Cache
- ();
- virtual
- std
- ::
- string
- GetName
- ()
- const
- ;
- protected
- :
- static
- std
- ::
- map
- <
- std
- ::
- string
- ,
- Cache
- *>
- cache_map_
- ;
- std
- ::
- string name_
- ;
- private
- :
- static
- int
- MAX_CACHE_NUM
- ;
- static
- std
- ::
- map
- <
- std
- ::
- string
- ,
- DataMap
- *>
- cache_store_
- ;
- };
复制代码
持久化
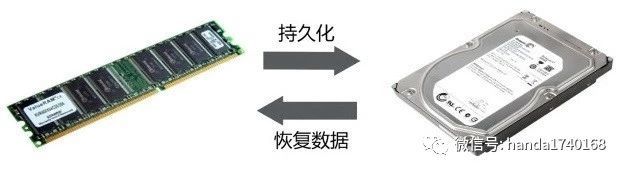
长久以来,互联网的应用会使用类似MySQL这一类SQL数据库来存储数据。当然也有很多游戏是使用SQL数据库的,后来业界也出现“数据连接层”(DAL)的设计,其目的就是当需要更换不同的数据库时,可以不需要修改大量的代码。但是这种设计,依然是基于SQL这种抽象。然而不久之后,互联网业务都转向NoSQL的存储模型。实际上,游戏中对于玩家存档的数据,是完全可以不需要SQL这种关系型数据库的了。早期的游戏都是把玩家存档存放到文件里,就连游戏机如PlayStation,都是用存储卡就可以了。
一般来说,游戏中需要存储的数据会有两类:
玩家的存档数据
游戏中的各种设定数据
对于第一种数据,用Key-Value的方式基本上能满足。而第二种数据的模型可能会有很多种类,所以不需要特别的去规定什么模型。因此我设计了一个key-value模型的持久化结构。
- /**
- * @brief 由于持久化操作一般都是耗时等待的操作,所以需要回调接口来通知各种操作的结果。
- */
- class
- DataStoreCallback
- {
- public
- :
- static
- int
- MAX_HANG_UP_CALLBACK_NUM
- ;
- // 最大回调挂起数
- std
- ::
- string key
- ;
- Serializable
- *
- value
- ;
- DataStoreCallback
- ();
- virtual
- ~
- DataStoreCallback
- ();
- /**
- * 当 Init() 初始化结束时会被调用。
- * @param result 是初始化的结果。0 表示初始化成功。
- * @param msg 是初始化可能存在的错误信息。可能是空字符串 “”。
- */
- virtual
- void
- OnInit
- (
- int
- result
- ,
- const
- std
- ::
- string
- &
- msg
- );
- /**
- * 当调用 Get() 获得结果会被调用
- * @param key
- * @param value
- * @param result 是 0 表示能获得对象,否则 value 中的数据可能是没有被修改的。
- */
- virtual
- void
- OnGot
- (
- const
- std
- ::
- string
- &
- key
- ,
- Serializable
- *
- value
- ,
- int
- result
- );
- /**
- * 当调用 Put() 获得结果会被调用。
- * @param key
- * @param result 如果 result 是 0 表示写入成功,其他值表示失败。
- */
- virtual
- void
- OnPut
- (
- const
- std
- ::
- string
- &
- key
- ,
- int
- result
- );
- /**
- * 当调用 Remove() 获得结果会被调用
- * @param key
- * @param result 返回 0 表示删除成功,其他值表示失败,如这个 key 代表的对象并不存在。
- */
- virtual
- void
- OnRemove
- (
- const
- std
- ::
- string
- &
- key
- ,
- int
- result
- );
- /**
- * 准备在发起用户设置的回调,如果使用者没有单独为一个回调事务设置单独的回调对象。
- * 在 PrepareRegisterCallback() 中会生成一个临时对象,在此处会被串点参数并清理。
- * @param privdata 由底层回调机制所携带的回调标识参数,如果为 NULL 则返回 NULL。
- * @param init_cb 初始化时传入的共用回调对象
- * @return 可以发起回调的对象,如果为 NULL 表示参数 privdata 是 NULL
- */
- static
- DataStoreCallback
- *
- PrepareUseCallback
- (
- void
- *
- privdata
- ,
- DataStoreCallback
- *
- init_cb
- );
- /**
- * 检查和登记回调对象,以防内存泄漏。
- * @param callback 可以是NULL,会新建一个仅仅用于存放key数据的临时callback对象。
- * @return 返回一个callback对象,如果是 NULL 表示有太多的回调过程未被释放。
- */
- static
- DataStoreCallback
- *
- PrepareRegisterCallback
- (
- DataStoreCallback
- *
- callback
- );
- protected
- :
- static
- int
- kHandupCallbacks
- ;
- /// 有多少个回调指针被挂起,达到上限后会停止工作
- };
- /**
- *@brief 用来定义可以持久化对象的数据存储工具接口
- */
- class
- DataStore
- :
- public
- Component
- {
- public
- :
- DataStore
- (
- DataStoreCallback
- *
- callback
- =
- NULL
- )
- :
- callback_
- (
- callback
- )
- {
- // Do nothing
- }
- virtual
- ~
- DataStore
- ()
- {
- // Do nothing
- }
- /**
- * 初始化数据存取设备的方法,譬如去连接数据库、打开文件之类。
- * @param config 配置对象
- * @param callback 参数 callback 为基本回调对象,初始化的结果会回调其 OnInit() 函数通知用户。
- * @return 基本的配置是否正确,返回 0 表示正常。
- */
- virtual
- int
- Init
- (
- Config
- *
- config
- ,
- DataStoreCallback
- *
- callback
- );
- virtual
- int
- Init
- (
- Application
- *
- app
- ,
- Config
- *
- cfg
- ){
- app_
- =
- app
- ;
- return
- Init
- (
- cfg
- ,
- callback_
- );
- }
- virtual
- std
- ::
- string
- GetName
- ()
- {
- return
- “den::DataStore”
- ;
- }
- virtual
- int
- Stop
- ()
- {
- Close
- ();
- return
- 0
- ;
- }
- /**
- * 驱动存储接口程序运行,触发回调函数。
- * @return 返回 0 表示此次没有进行任何操作,通知上层本次调用后可以 sleep 一下。
- */
- virtual
- int
- Update
- ()
- =
- 0
- ;
- /**
- * 关闭程序,关闭动作虽然是异步的,但不再返回结果,直接关闭就好。
- */
- virtual
- void
- Close
- ()
- =
- 0
- ;
- /**
- * 读取一个数据对象,通过 key ,把数据放入到 value,结果会回调通知 callback。
- * 发起调用前,必须把 callback 的 value 字段设置为输出参数。
- * @param key
- * @param callback 如果NULL,则会回调从 Init() 中传入的 callback 对象。
- * @return 0 表示发起请求成功,其他值为失败
- */
- virtual
- int
- Get
- (
- const
- std
- ::
- string
- &
- key
- ,
- DataStoreCallback
- *
- callback
- =
- NULL
- )
- =
- 0
- ;
- /**
- * 写入一个数据对象,写入 key ,value,写入结果会回调通知 callback。
- * @param key
- * @param value
- * @param callback 如果是 NULL,则会回调从 Init() 中传入的 callback 对象。
- * @return 表示发起请求成功,其他值为失败
- */
- virtual
- int
- Put
- (
- const
- std
- ::
- string
- &
- key
- ,
- const
- Serializable
- &
- value
- ,
- DataStoreCallback
- *
- callback
- =
- NULL
- )
- =
- 0
- ;
- /**
- * 删除一个数据对象,通过 key ,结果会回调通知 callback。
- * @param key
- * @param callback 如果是 NULL,则会回调从 Init() 中传入的 callback 对象。
- * @return 表示发起请求成功,其他值为失败
- */
- virtual
- int
- Remove
- (
- const
- std
- ::
- string
- &
- key
- ,
- DataStoreCallback
- *
- callback
- =
- NULL
- )
- =
- 0
- ;
- protected
- :
- /// 存放初始化传入的回调指针
- DataStoreCallback
- *
- callback_
- ;
- };
复制代码
针对上面的DataStore模型,可以实现出多个具体的实现:
文件存储
Redis
其他的各种数据库
基本上文件存储,是每个操作系统都会具备,所以在测试和一般场景下,是最方便的用法,所以这个是一定需要的。
在游戏的持久化数据里面,还有两类功能是比较常用的,一种是排行榜的使用;另外一种是拍卖行。这两个功能是基本的Key-Value无法完成的。使用SQL或者Redis一类NOSQL都有排序功能,所以实现排行榜问题不大。而拍卖行功能,则需要多个索引,所以只有一个索引的Key-Value NoSQL是无法满足的。不过NOSQL也可以“手工”的去建立多个Key的记录。不过这类需求,还真的很难统一到某一个框架里面,所以设计也是有限度,包含太多的东西可能还会有反效果。因此我并不打算在持久化这里包含太多的模型。
原创文章,作者:棋牌游戏,如若转载,请注明出处:https://www.qp49.com/2019/04/11/1991.html